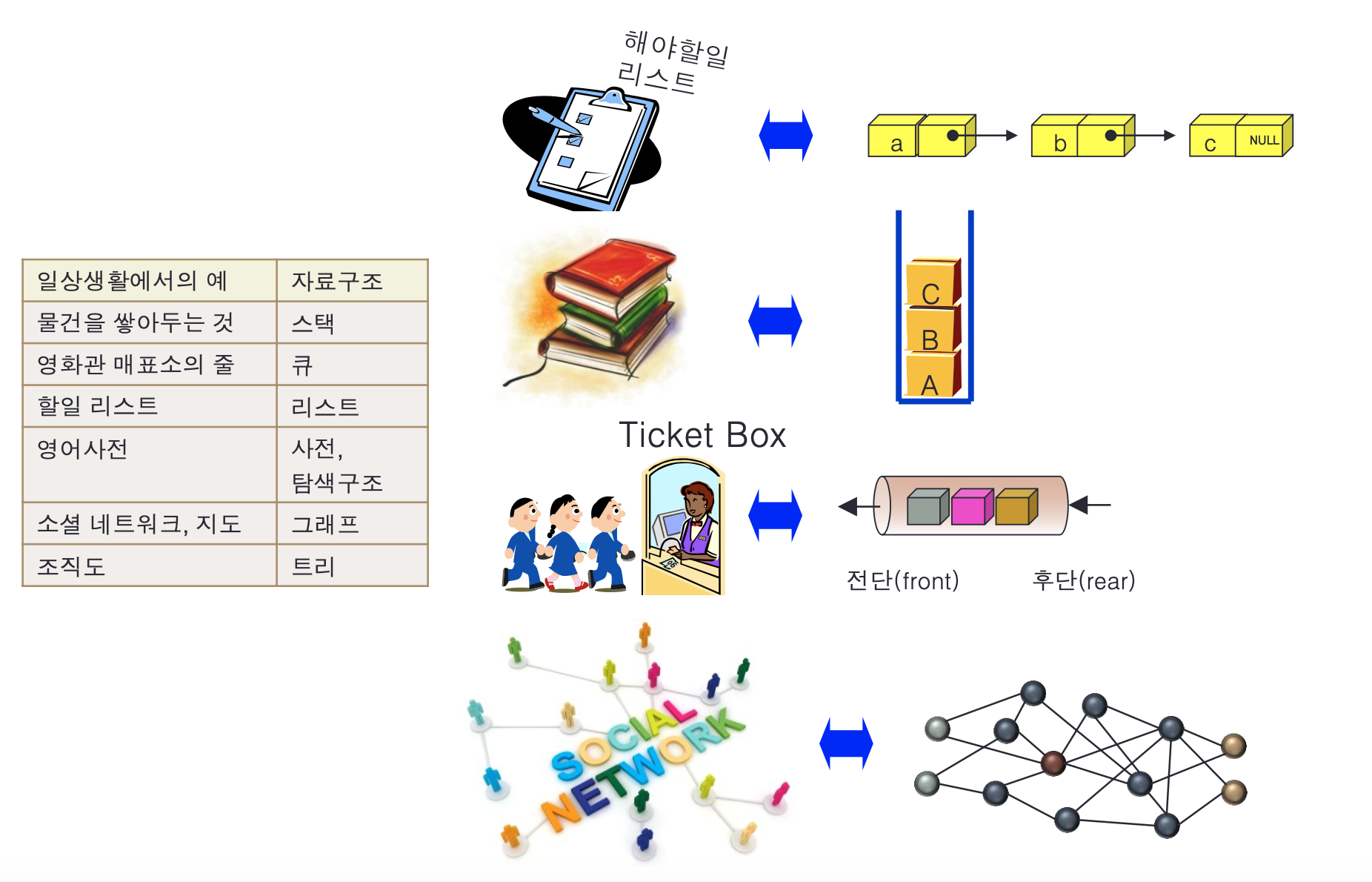
자료구조란?
간단하게 말해서 자료를 정리하여 보관하기 위해 여러 가지 구조를 이용한 것이 자료구조 라고 합니다
자료구조의 분류
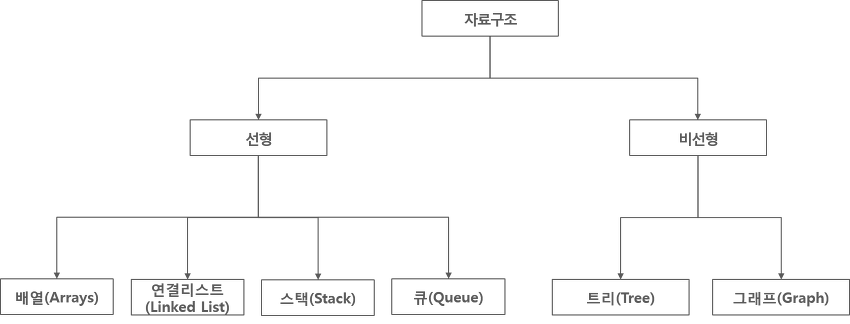
자료구조는 숫자나 문자와 같은 단순 자료구조와 여러 자료를 한꺼번에 보관하는 복합 자료구조로 나눌 수 있습니다
주로 선형과 비선형으로 나눌수 있습니다
선형 자료구조
자료를 일렬로 나열할 수 있는 구조를 말합니다 자료들 사이에는 반드시 순서가 있어야 합니다 주로 스텍,큐,덱 은 자료의 접근이 전단과 후단으로만 제한되는 선형 자료구조이고, 리스트는 임의의 위치에 있는 자료의 접근을 허용하는 가장 자유로운 선형 자료구조입니다.
하지만 set(집합) 은 원소들 사이에 순서가 없으므로 선형 자료구조로 볼수없습니다.
비선형 자료구조
한 줄로 나열하기 어려운 복잡한 관계의 자료들을 표현할 수 있는 자료구조입니다. 예를 들어 트리는 컴퓨터의 폴더 구조나 회사의 조직도
그래프는 지하철 노선도나 sns 인맥 지도와 같이 가장 복잡한 연결 관계를 갖는 자료를 잘 표현할 수 있습니다.
알고리즘
알고리즘은 주어진 문제를 해결하기 위한 단계적인 절차를 말합니다 컴퓨터는 어떤 일을 하는 절차를 표현하기 위해 명령어들을 사용하는데 결국 알고리즘은 특정한 일을 수행하는 명령어들의 집합으로 볼 수 있습니다.

알고리즘의 기술 방법
1. 자연어 표현
자연어를 사용하면 표현이 자유롭고 편리하다는 장점이 있지만 자칫 문장의 의미가 애매해질 수 있습니다. 따라서 사용되는 단어들의 의미를 정확히 해야만 알고리즘이 될 수 있습니다.
find_max (a,b,c)
a를 최대값을 저장하는 변수 max에 복사한다.
만약 b가 max보다 크면 b를 max에 복사한다.
만약 c가 max보다 크면 c를 max에 복사한다.
max를 반환한다.
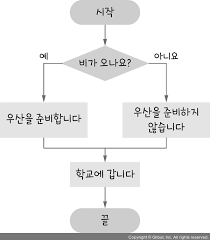
2. 흐름도(flowchart) 표현
흐름도는 알고리즘의 절차들을 가장 정확하게 표현할 수 있어서 특허 명세서 등에서 많이 사용됩니다. 그렇지만 알고리즘이 조금만 길어도 그림이 너무 복잡해져 혼란스러워진다는 문제가 있습니다.
3. 유사(슈도, pseudo code) 표현
유사 코드는 자연어보다는 체계적이지만 프로그래밍 언어보다는 덜 엄격한 방법입니다. 특히 프로그래밍 언어에서 발생하는 많은 불필요한 표현을 생략할 수 있어 알고리즘 자체에만 집중할 수 있고 따라서 논문이나 도서들에서 흔히 사용됩니다. 유사코드의 문법은 C와 같은 기존 언어들과 유사하지만, 대입(할당) 연산자로 '='이 아니라 '<-'를 사용하고, '='는 비교 연산자로 사용됩니다.
find_max(a,b,c)
max <- a // <- 는 대입 연산을 의미함
if b>max: // :는 새로운 블록의 시작을 나타냄
max<-b //tofhdns qmffhrdms emfduTmrlfh vytlgka
if c>max :
max <- c
retyrn max
추상 자료형
새로운 자료형을 정의하려면 먼저 자세하고 복잡한 내용 대신에 그 자료형에서 필수적이고 중요한 특징만 골라서 단순화시키는 작업이 필요합니다. 이를 추상화러고 하는데, 이러한 작업을 통해 정의한 자료형을 추상 자료형(Abstract Data Type, ADT)이라고 합니다."추상"이란
단어가 약간 부담스럽지만, 복잡한 것은 아닙니다. 추상 자료형은 그 자료형이 어떤 데이터를 다루고 그 데이터에 어떤 연산이 필요한지를 간략히 정리한 것 정도로 생각할 수 있습니다.
복잡도
요즘의 컴퓨터는 이전에 비해 엄청난 계산속도와 방대한 메모리를 자랑하고 있습니다. 그렇지만 프로그램을 작성할 때 계산시간을 줄이고 메모리를 효과적으로 사용하기 에 계속 노력해야 합니다.
1. 프로그램의 규모가 이전에 비해 엄청나게 커지고 있기 때문입니다. 처리할 자료의 양이 많아질수록 알고리즘의 효율성이 더욱 중요해집니다.
| 입력 자료의 개수 | 프로그램 A: n² | 프로그램 B:2ⁿ |
| n=6 | 36초 | 64초 |
| n=100 | 10000초 | 10²²년 |
2. 사용자들은 여전히 빠른 프로그램을 선호하기 때문입니다. 경쟁사보다 속도가 느리면 경쟁에서 밀릴 수밖에 없는데, 예를 들어 스마트폰에서 화면 터치 후 반응속도가 조금이라도 느리면 그 제품은 성공하기 어렵습니다. 따라서 프로그램 개발자는 하드웨어와는 상관없이 최선의 효율성을 갖는 알고리즘을 개발하도록 노력해야 합니다.
시간 복잡도 분석
구현하지 않고 알고리즘의 효율성을 평가하는 방법입니다. 처리시간을 직접 측정하는 대신에 알고리즘의 연산 횟수를 대략적으로 계산하는데, 더 많은 연산이 필요하면 더 복잡한 알고리즘이 됩니다. 공간복잡도는 메모리를 사용하는 크기, 나 공간을 보지만 주로 보는 것은 시간 복잡도입니다.
calc_sum1(n)
sum<-0
for i<-1 to n
sum <- sum+i
return sum1부터 n까지의 합 구하기를 for문으로 반복해서 단순한 코드를 사용했습니다.
1부터 n까지의 합 공식은 n * (n+1) /2입니다 알고리즘은 다음과 같습니다
calc_sum2(n)
sum <-n *(n+1)/2
return sum연산자와 *,+,/ 연산자가 각각 한 번씩 수행
이제 연산의 횟수를 계산해 보면 보통 연산의 실행 횟수는 입력의 크기 n에 대한 함수 형태로 나타나게 됩니다. 이를 복잡도 함수라고 합니다.

1번째 알고리즘은 전체 복잡도 함수는 T(n) = 2n+1 이
2번째 알고리즘은 T(n) = 4입니다 즉 무조건 4번 연산만 하고 첫 번째 연산은 입력값이 높으면 높을수록 연산값이 계속 올라갑니다
점근적 표기
복잡도를 나타낼 때 여러 항을 갖는 복잡도 함수를 최고치항만 계수 없이 취해 단순하게 표현하는 방법을 사용합니다.
예를 들어 n²+2는 n²으로 8848n+200000 은 단순하게 n으로 나타내는 것입니다. 즉, 정확히 몇 번인가 가 아닌 증가 속도만을 표현하는 것입니다.
빅오 (big -O ) 표기법
알고리즘의 복잡도를 O(g(n))와 같이 나타내는 방법입니다. O(g(n))은 증가 속도가 g(n)과 같거나 낮은 모든 복잡도 함수를 모두 포함하며 처리시간의 상한을 의미합니다 즉 연산을 해서 최악의 시나리오로 최대 연산 횟수가 나온 값이라고 생각하면 됩니다.
빅 오메가 표기법
최선의 연산값이 나온 것
빅 세타 표기법
평균



