생활에서 가장 많이 사용하는 자료구조중 하나 입니다.
리스트는 자료들이 차례대로 나열된 선형 자료구조 입니다 이때 각 자료는 반드시 순서 또는 위치를 갖습니다
스택이나 큐,덱 에서 자료의 접근이 전단이나 후단으로 제한되는 것과 달리 리스트에서는 어떤 위치에서도 자료를 넣거나 꺼낼 수 있습니다.
따라서 가장 활용이 자유로운 선형자료구조 입니다.
리스트의 특징중 하나는 중간에 자료를 삽입하면 이후 모든 자료가 뒤로 한 칸 씩밀립니다
리스트와 비슷한 개념으로 집합(set) 이 있습니다. 리스트와 달리 set은 원소의 중복을 허용하지 않고 , 특히 원소들 사이에 순서가 없습니다 따라서 set 은 자료들 순서대로 나열할 수 있는 선형 자료구조로 볼수없습니다
| 명령어 | 설명 |
| insert(pos,e) | pos 위치에 새로운 요소 e를 삽입한다 |
| delete(pos) | pos 위치에 있는 요소를 꺼내고(삭제) 반환한다. |
| is_empty() | 리스트가 비어 있는지를 검사한다 |
| is_full() | 리스트가 가득 차 있는지를 검사한다 |
| get_entry(pos) | pos위치에 있는 요소를 반환한다. |
배열을 이용한 리스트는 그말대로 기존 배열과 사용하는것이 거의 동일하며 size함수는 마지막요소 바로 앞을 가리킵니다
공백상태와 포화 상태를 검사할때
공백 상태는 size가 0 인 경우이고 포화 상태는 size가 MAX_SIZE와 같을 때 입니다 추기화는 리스트를 공백상태로 만드는 것이므로 size를 0으로 초기화 하면 됩니다.
배열을 이용한 리스트
배열을 이용한 리스트는 그 말대로 기존 배열과 사용하는 것이 거의 동일하며, size 함수는 마지막 요소 바로 앞을 가리킵니다. 공백 상태와 포화 상태를 검사할 때, 공백 상태는 size가 0인 경우이고, 포화 상태는 size가 MAX_SIZE와 같을 때입니다. 초기화는 리스트를 공백 상태로 만드는 것이므로 size를 0으로 초기화하면 됩니다.
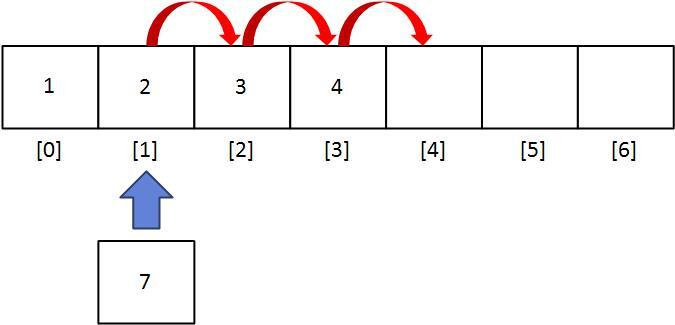
1. insert(pos, e) 연산
pos에 새로운 요소 e를 삽입하는 연산은 다음과 같은 순서로 수행됩니다:
- 마지막 요소부터 pos 위치까지의 요소들을 한 칸씩 뒤로 옮깁니다. (맨 뒤에서부터 옮기는 이유는 값이 복사되지 않도록 하기 위함입니다.)
- pos 위치에 e를 삽입합니다.
- 리스트의 크기(size)를 1 증가시킵니다.
2. delete(pos) 연산
pos 위치의 요소를 꺼내서 반환하는 연산은 다음과 같은 순서로 수행됩니다:
- pos 위치의 요소를 반환 값으로 저장합니다.
- pos 다음 위치부터 마지막 요소까지의 요소들을 한 칸씩 앞으로 옮깁니다.
- 리스트의 크기(size)를 1 감소시킵니다.

3. get_entry(pos) 연산
pos 위치의 요소를 참조하는 연산으로, 이 연산은 배열에서의 인덱스 접근과 동일하므로 시간복잡도는 O(1)입니다.
단순 연결 리스트
단순 연결 리스트는 각 노드가 데이터와 다음 노드를 가리키는 포인터를 포함하는 구조입니다. 첫 번째 노드를 가리키는 포인터를 헤드 포인터라 합니다.
1. 해더 포인터 설명
헤더 포인터는 리스트의 첫 번째 노드를 가리키며, 이를 통해 리스트의 시작점을 알 수 있습니다.
2. get_node(pos), get_entry(pos) 연산
- get_node(pos) : pos 위치의 노드를 반환합니다.
- get_entry(pos) : pos 위치의 노드의 데이터를 반환합니다.
이 명령어들의 시간복잡도는 O(n)입니다. pos 위치까지 노드를 순차적으로 탐색해야 하기 때문입니다.
3. insert(pos, e) 연산
pos 위치에 요소 e를 삽입하는 연산의 순서는 다음과 같습니다:
- 새로운 노드를 생성하여 e를 저장합니다.
- pos-1 위치의 노드를 찾아, 새로운 노드를 이 노드의 다음으로 연결합니다.
- 새로운 노드의 다음을 기존 pos 위치의 노드로 연결합니다.

4. delete(pos) 연산
pos 위치의 요소를 꺼내서 반환하는 연산의 순서는 다음과 같습니다:
- pos-1 위치의 노드를 찾아, pos 위치의 노드를 다음 노드로 연결합니다.
- pos 위치의 노드를 삭제하고 데이터를 반환합니다.
- 만약 삭제할 노드의 선행노드 before를 미리 알고 있다면 삭제 연산의 시간복잡도는 O(1)이며, 배열 구조보다 훨씬 유리합니다.

5. 다양한 연산
- append(e) : 리스트의 끝에 요소 e를 추가합니다.
- pop() : 리스트의 마지막 요소를 삭제하고 반환합니다.
6. 헤드 포인터와 헤드 노드
헤드 포인터는 리스트의 첫 번째 노드를 가리키고, 헤드 노드는 데이터를 저장하지 않으며 첫 번째 실제 노드를 가리키는 역할을 합니다.
이중 연결 리스트의 구조
이중 연결 리스트는 각 노드가 데이터와 함께 앞 노드와 뒤 노드를 가리키는 두 개의 포인터를 가지는 구조입니다.
이중 연결 리스트의 기본적인 연산들
- insert(pos, e) : pos 위치에 요소 e를 삽입합니다.
- delete(pos) : pos 위치의 요소를 삭제하고 반환합니다.
9. insert(pos, e) 연산
- 새로운 노드를 생성하여 e를 저장합니다.
- pos-1 위치의 노드와 pos 위치의 노드를 찾습니다.
- 새로운 노드를 이들 사이에 삽입합니다.
- 새로운 노드의 이전 노드를 pos-1 노드로, 다음 노드를 pos 노드로 연결합니다.
- pos-1 노드의 다음을 새로운 노드로, pos 노드의 이전을 새로운 노드로 연결합니다.
10. delete(pos) 연산
- pos 위치의 노드를 찾아 이전 노드와 다음 노드를 연결합니다.
- pos 위치의 노드를 삭제하고 데이터를 반환합니다.
- 삭제 연산도 O(n)의 시간복잡도를 가지고 있습니다 하지만 미리 삭제할 노드 의 위치를 알고있다면 O(1)이 될수있습니다.



